


When a deep network is trained on a high-level task such as classifying a place or synthesizing a scene, individual neural units within the network will often emerge that match specific human-interpretable concepts, like "trees", "windows", or "human faces."
What role do such individual units serve within a deep network?
We examine this question in two types of networks that contain interpretable units: networks trained to classify images of scenes (supervised image classifiers), and networks trained to synthesize images of scenes (generative adversarial networks).
Dissecting Units in Classifiers and Generators
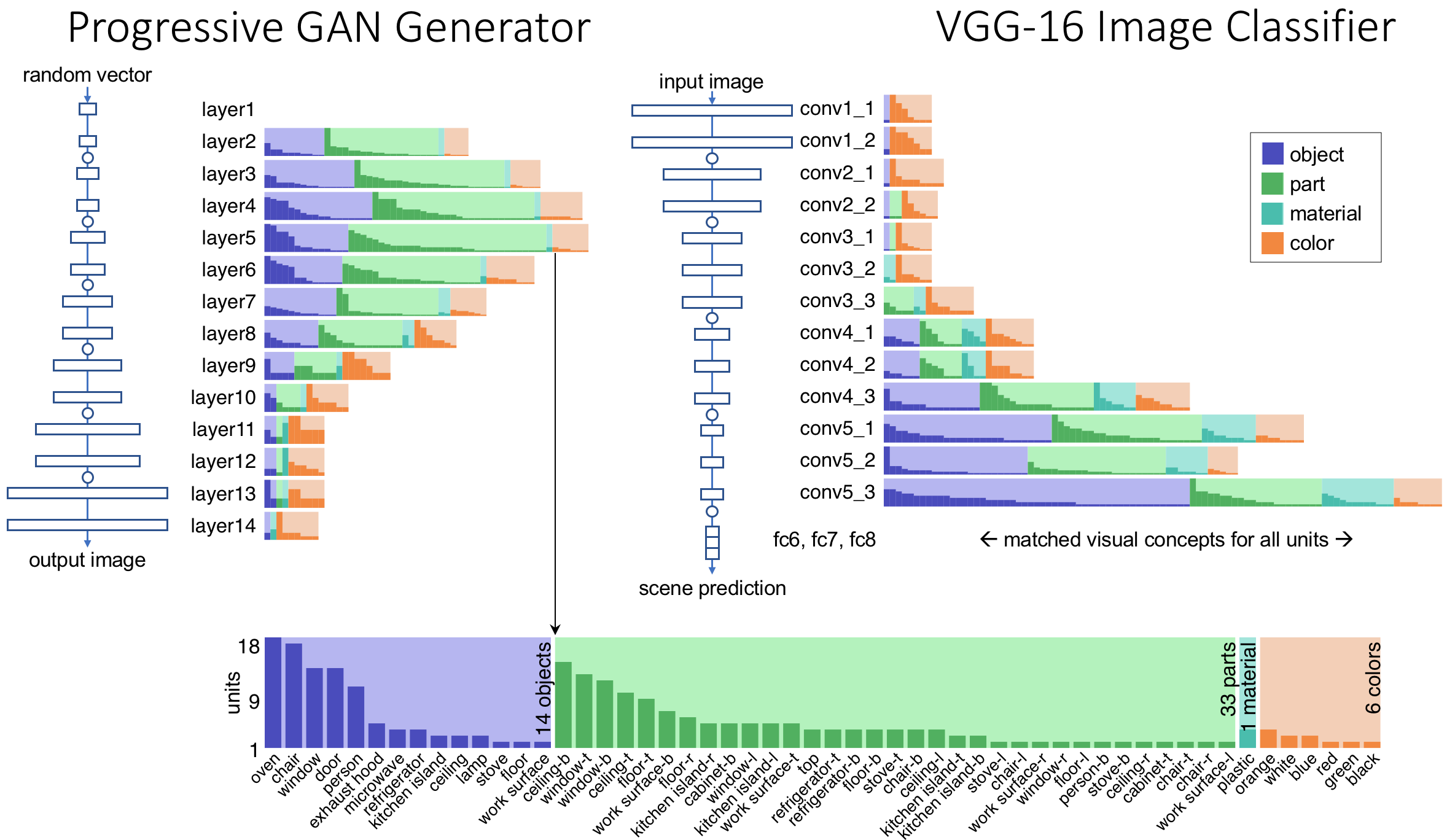
To identify units that match human concepts, we compare their output to the outputs of a semantic segmentation network that has been trained to label pixels with a broad set of object, part, material and color classes. This technique, called network dissection, gives us a standard and scalable way to identify any units within the networks we analyze that match those same semantic classes.
The analysis can be applied both in classification settings where the image is the input, and in generative settings where the image is the output.
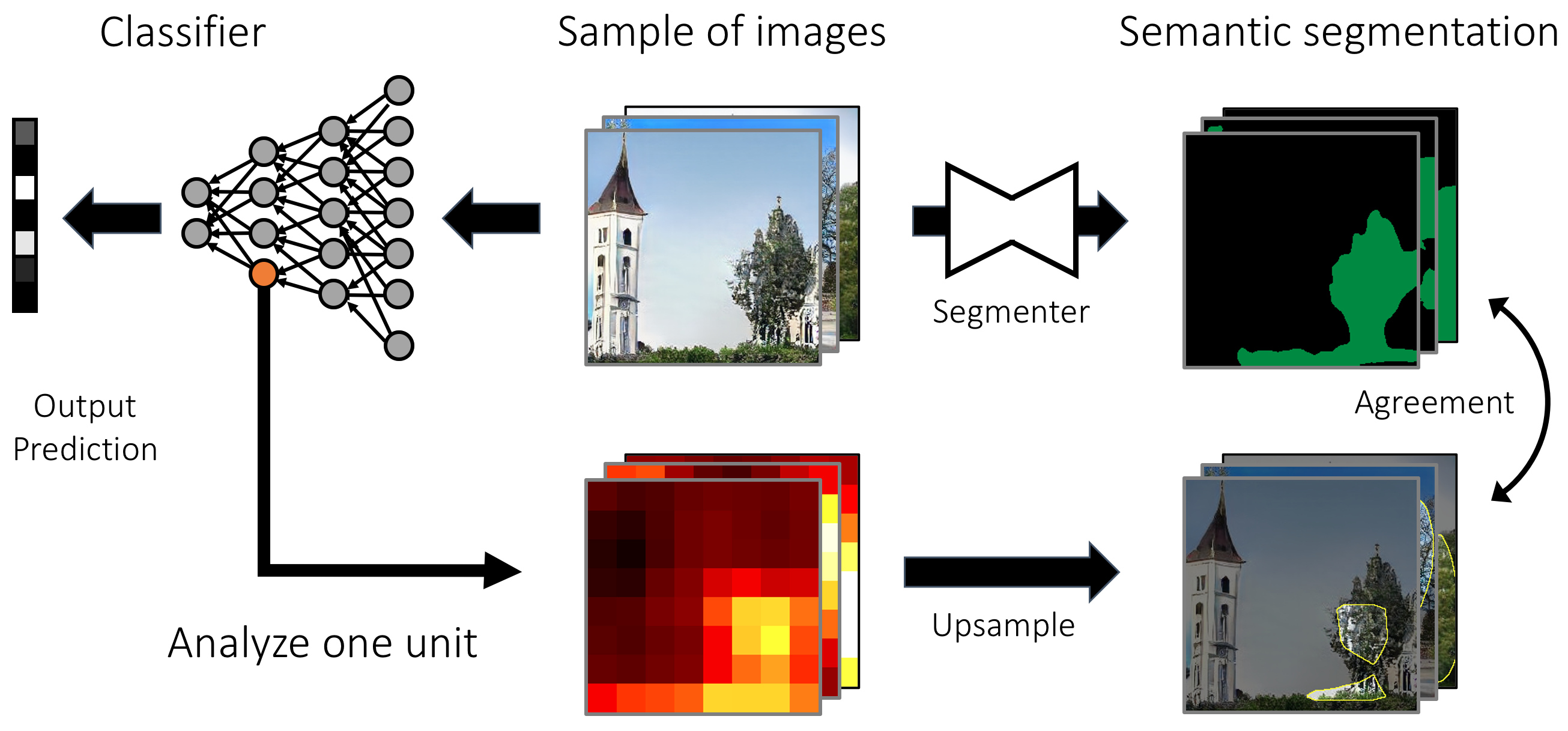
Network dissection allows us to quantify and compare unit semantics between layers and networks. We find that both state-of-the-art GANs and classifiers contain object-matching units that correspond to a variety of object and part concepts, with semantics emerging in different layers.
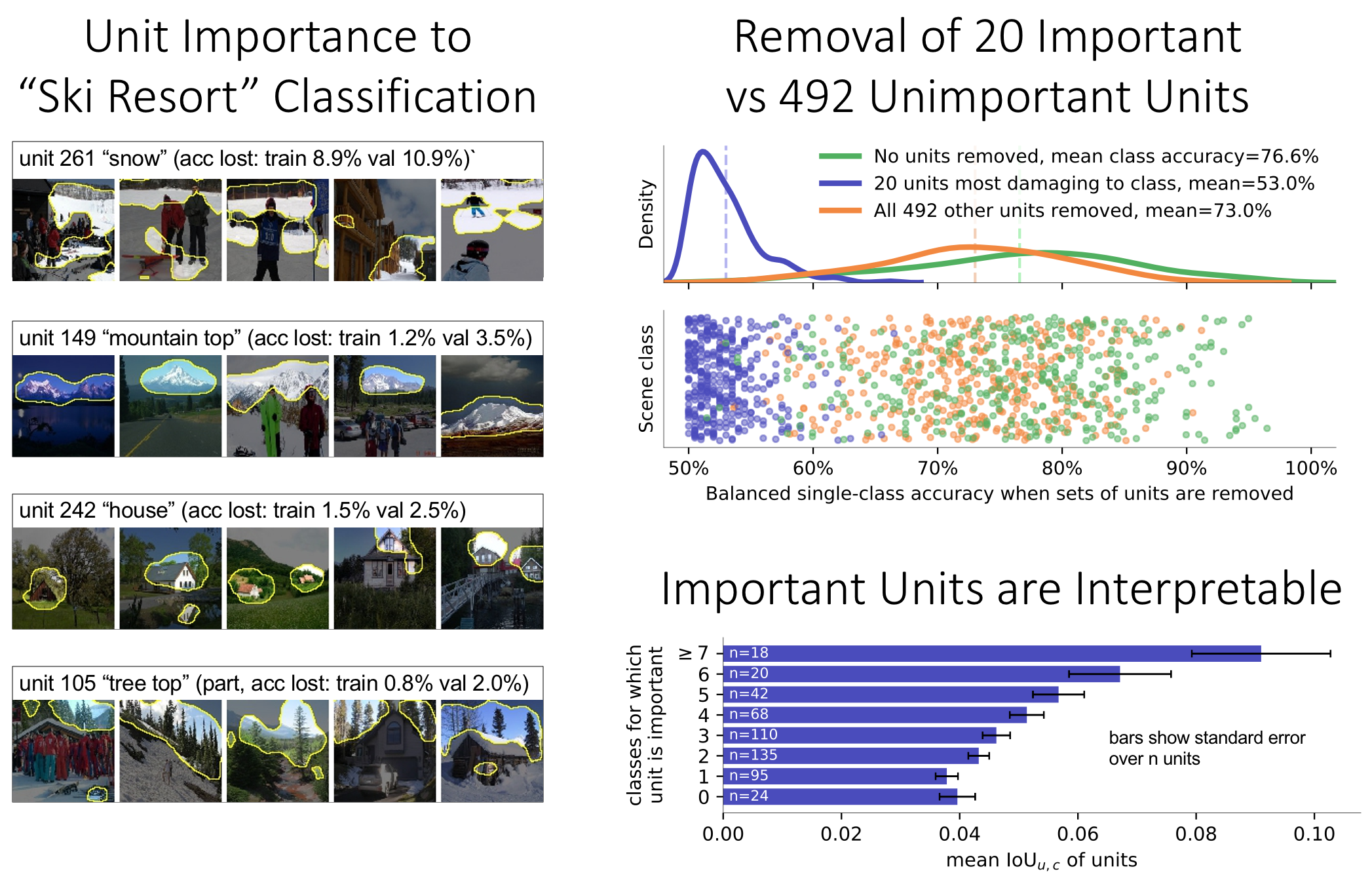
To investigate the role of such units within classifiers, we measure the impact on the accuracy of the network when we turn off units individually or in groups. We find that removing as few as 20 units can destroy the network's ability to detect a class, but retaining only those 20 units and removing 492 other units in the same layer can keep the network's accuracy on that same class mostly intact. Furthermore, we find that those units that are important for the largest number of output classes are also the emergent units that match human-interpretable concepts best.
In a generative network, we can understand causal effects of neurons by observing changes to output images when sets of units are turned on and off. We find causal effects are strong enough to enable users to paint images out of object classes by activating neurons; we also find that some units reveal interactions between objects and specific contexts within a model.
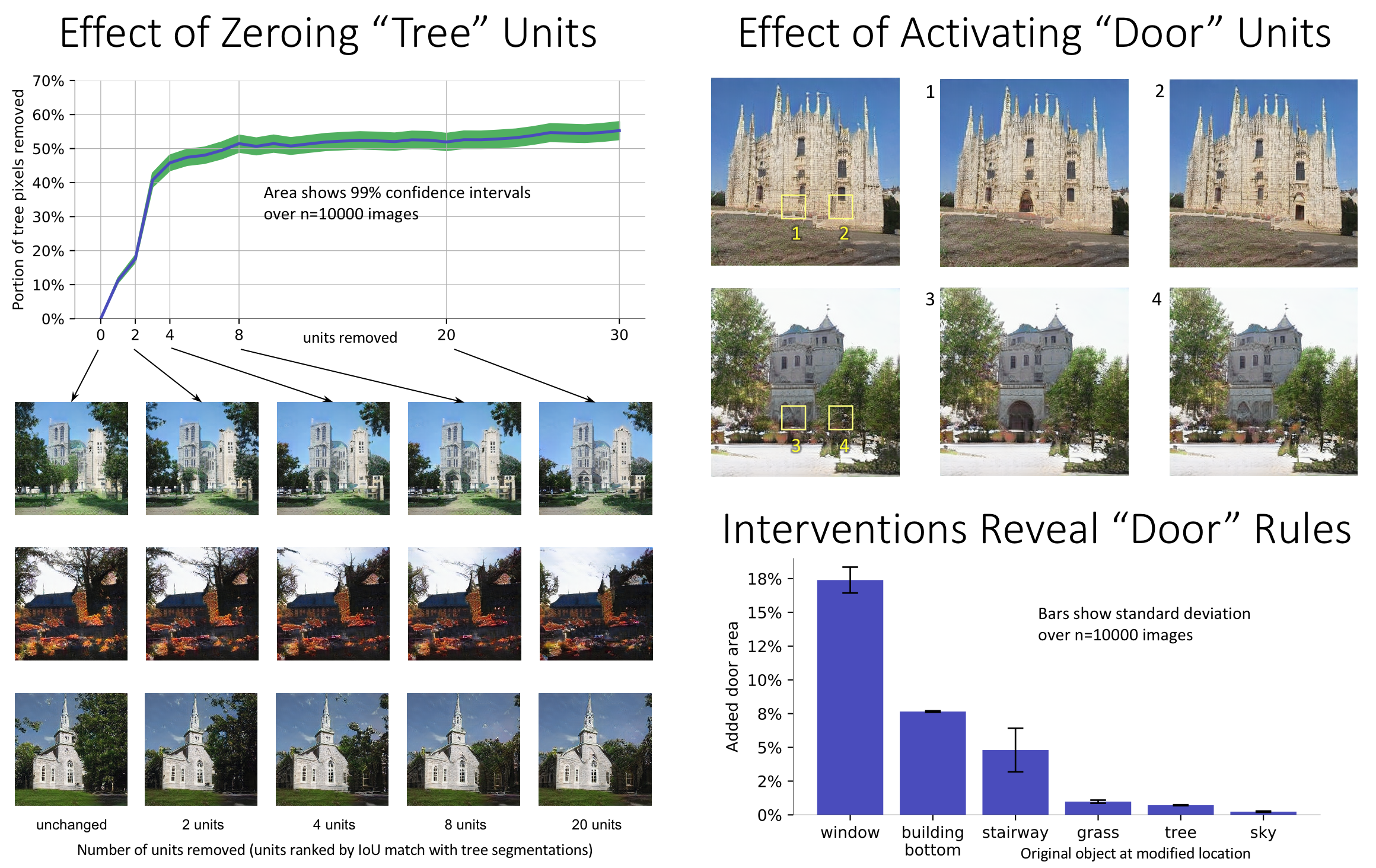
Interactive Interventions
Identifying casual effects of neurons enables new types of applications. For example, by activating and deactivating neurons accordiing to a user's gestures, we can use a generative network as a semantic paintbrush that allows you to add, remove, and change objects and architctural features in a scene. A demo of this application is available here.
Also See
This paper builds upon the following previous work presented at conferences.
 David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, Antonio Torralba. Network Dissection: Quantifying Interpretability of Deep Visual Representations. Computer Vision and Pattern Recognition (CVPR), 2017.
This paper proposed identifying interpretable units by examining behavior on a human-labeled segmentation data set. In the current work we generalize this idea by using a segmentation network, which allows us to test using images that the network was trainied on; also generative networks can be tested using the same method. In the current work we now also examine the causal role of units.
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, Antonio Torralba. Network Dissection: Quantifying Interpretability of Deep Visual Representations. Computer Vision and Pattern Recognition (CVPR), 2017.
This paper proposed identifying interpretable units by examining behavior on a human-labeled segmentation data set. In the current work we generalize this idea by using a segmentation network, which allows us to test using images that the network was trainied on; also generative networks can be tested using the same method. In the current work we now also examine the causal role of units.
 David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B. Tenenbaum, William T. Freeman, Antonio Torralba. GAN Dissection: Visualizing and Understanding Generative Adversarial Networks. Proceedings of the International Conference on Learning Representations (ICLR), 2019.
This paper introduced the use of a segmentation network and interventions to probe the structure of the network. The current work further quantifies the effect of changing sets of units in a generator, and shows that similar methods can be used on classifiers and allows a comparison between the classification and generative case.
David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B. Tenenbaum, William T. Freeman, Antonio Torralba. GAN Dissection: Visualizing and Understanding Generative Adversarial Networks. Proceedings of the International Conference on Learning Representations (ICLR), 2019.
This paper introduced the use of a segmentation network and interventions to probe the structure of the network. The current work further quantifies the effect of changing sets of units in a generator, and shows that similar methods can be used on classifiers and allows a comparison between the classification and generative case.
Citation
Bibtex
@article{bau2020units,
author = {Bau, David and Zhu, Jun-Yan and Strobelt, Hendrik and Lapedriza, Agata and Zhou, Bolei and Torralba, Antonio},
title = {Understanding the role of individual units in a deep neural network},
elocation-id = {201907375},
year = {2020},
doi = {10.1073/pnas.1907375117},
publisher = {National Academy of Sciences},
issn = {0027-8424},
URL = {https://www.pnas.org/content/early/2020/08/31/1907375117},
journal = {Proceedings of the National Academy of Sciences}
}
Data Availability
The code posted on github contains the analysis needed to reproduce the results in the paper. It also includes scripts for setting up all the dependencies using conda, and scripts to download the datasets and models used in the analysis of the paper. The models and datasets can also be downloaded directly (in pytorch formats) here: